YOLO v2
在熟悉了前置算法 faster rcnn、ssd 和 yolov1 后理解 yolov2 算法就会非常轻松,因为他本质上没有提出全新的思想,而是基于前人所提思想对 yolov1 进行改进而已。其主要特点可以归纳如下:
引入了 BN 层、新的骨架网络和特征增强模块
引入了流行的 anchor 框设计,并且 anchor 设置直接采用 kmean 算法得到,不需要人为设置,更加友好
采用了高分辨率分类器微调训练以及多尺度检测器训练等等训练 trick
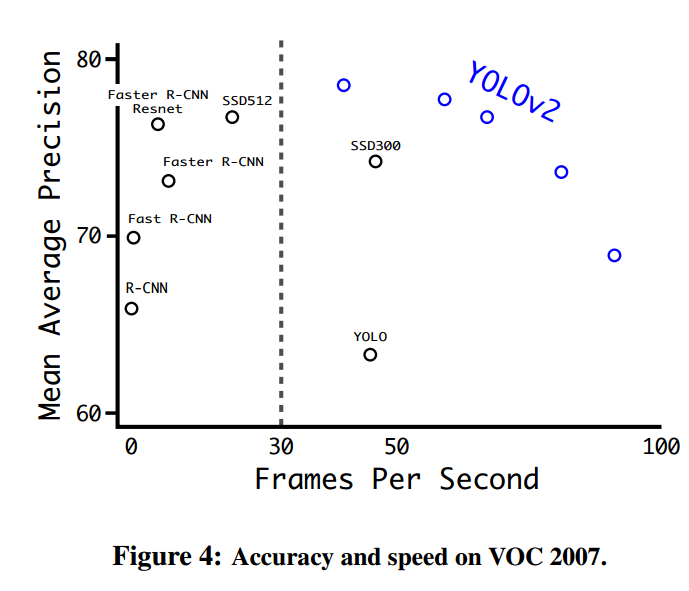
通过这些改进,大幅提升了 yolov1 的定位准确度和召回率,同时速度也是极快,如下图所示:
1 算法分析
1.1 backbone 模块
由于此时 BN 层已成为主流模块,可以大幅提高网络收敛速度和泛化能力,基于此作者设计了新的骨架网络称为 darknet19,其结构如下:
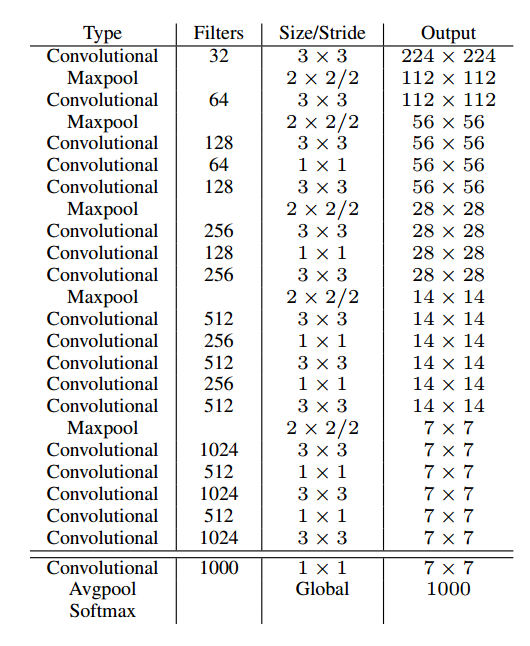
因为除了分类部分整个网络包括 19 层卷积,故命名为 darknet19,每个 convolutional 都包括 conv+bn+leakyrelu 模块,可以明显看出其是标准的和 vgg 相同的直筒结构。该分类网络首先在 imagenet 上面进行重新训练,然后把最后的 conv+avg+softmax 去掉,得到骨架权重作为目标检测的预训练权重。
1.2 head 模块
假设网络输入大小是 416x416,那么骨架网络最后层输出 shape 为(b,1024,13,13),也就是说采用固定 stride=32。如果直接在骨架网络最后一层再接几个卷积层,然后进行预测完全没有问题。作者认为 13x13 的特征图对于大物体检测来说是够了,但是对于小物体,特征图提供的信息就不一定够了,很可能特征已经消失了,故作者结合特征融合思想,提出一种新的 passthrough 层来产生更精细的特征图,本质上是一种特征聚合操作,目的是增强小物体特征图信息。如下所示:
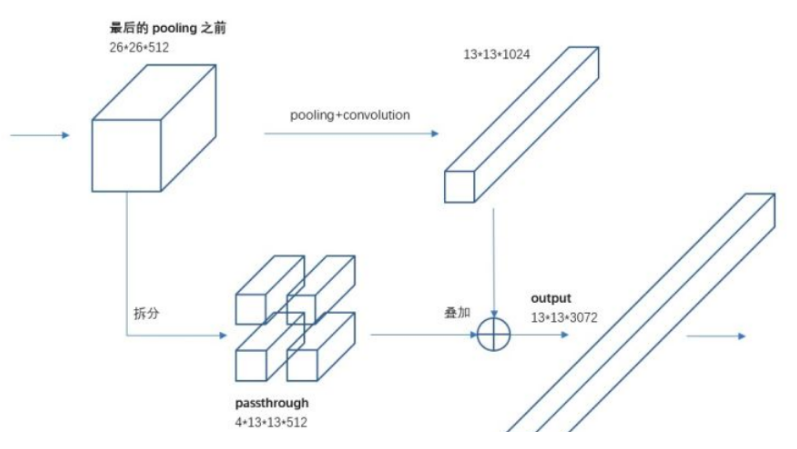
上面的第一个输入箭头是 darknet-19 的最后一个 max pool 运行前的特征图,假设图片输入是 416x416,那么最后一个 max pool 层输入尺度为 26x26x512,在该层卷积输出后引入一个新的分支:passthrough 层,将原来尺度为 26x26x512 特征图拆分 13x13x2048 的特征图,然后和 darkent-19 骨架最后一层卷积的 13x13x1024 特征图进行 concat,得到 13x13x3072 的特征图,然后经过 conv+bn+leakyrelu,得到最终的预测图。下面有打印网络结构图,更加容易理解。
上面的图通道画的不对,实际上由于通道太大了,消耗内存太多,故作者实际上做法是先将 26x26x512 降维为 26x26x64,然后拆分为 13x13x256,concat 后,得到 13x13x1280 的特征图。
采用 darknet 库代码打印网络结构如下所示:
其中26是1x1x64卷积核,27是reorg特征重排层(passthrough),25和28是快捷连接,31是loss层,故总共网络一共是31层,28和24连接处是拼接操作。
对于 reorg 的具体操作如下:
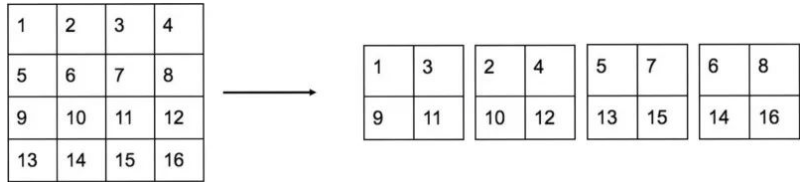
很容易理解,就是对每个 2x2 的格子进行切分,然后变成 4 个通道。那么这样做的好处是啥?为了讲清楚这个问题,需要引入一个新知识点:sub-pixel upsample 或者亚像素卷积,其可视化操作如下所示:
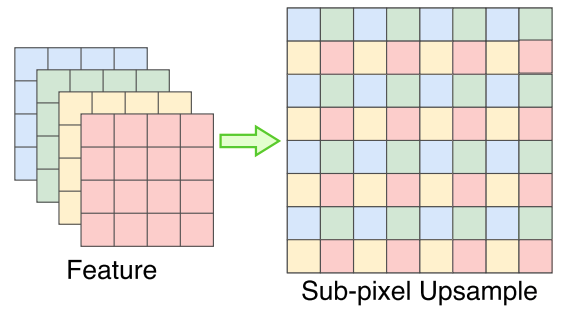
仔细观察可以看出,reorg 其实就是亚像素卷积的反向操作。亚像素卷积是一种替代简单上采样的操作,在超分辨率任务中是基本操作,目的是由小图得到大图,好处是可以对高层特征编码进更多的空间信息,如果在前面连接卷积操作,就可以变成可学习上采样了,所以亚像素卷积比双线性插值(不可学习)和反卷积(会强制补 0)要好。那么 reorg 的好处也就很容易理解了:可以最大程度保证不丢失空间信息,且总信息量不变,保证能够和低分辨率特征融合。
1.3 正负样本定义
为了说明正负样本定义,需要先分析 anchor 设定。为了克服 yolov1 里面每个网格最多只能检测单个物体的缺陷,和 faster rcnn 和 ssd 一样也引入了 anchor 设置。其设定每个网格一共 5 个 anchor,这 5 个 anchor 也不需要手动设计,而是通过 Kmean 算法自动计算得到,其计算过程为:
设定 Kmean 聚类个数 n 即为 anchor 个数
统计整个数据集上面的所有 bbox 的宽高,然后随机选择 n 个聚类中心,运行 kmean 算法,将 1-iou 作为距离准则,不断迭代,直到 kmean 的 n 个聚类中心不再变化为止,此时就得到了 n 个 anchor 的 wh 值
具体距离准则公式为:
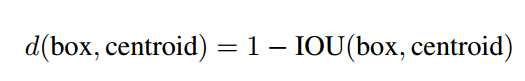
box 是所有统计的 bbox 的 wh,centroid 是聚类中心。
需要注意的是:为了更好将聚类后的 anchor 和 gt bbox 匹配,最好将所有图片采用和训练时一样的数据增强策略处理,并且统一到网络输入大小后,再统计数据集的 bbox 宽高,可以模拟尽可能多的数据分布,统计会更加精确。yolov2 在 coco 数据集上的典型 anchor 比例如下:
其数值含义是原图尺度聚类 anchor 除以 stride 得到的在特征图尺度上的值。
假设输入是 416x416,那么输出层是 13x13,head 预测层输出 shape 为(b,5*(xywh+conf+cls_num),13,13),一共 13x13x5=845 个 anchor。
(1) 正负属性定义
在设定 anchor 后就需要对每个 anchor 位置样本定义正负属性了。其规则和 yolov1 一样简单:保证每个 gt bbox 一定有一个唯一的 anchor 进行对应,匹配规则就是 IOU 最大。具体就是:对于某个 gt bbox,首先要确定其中心点要落在哪个网格内,然后计算这个网格的 5 个 anchor 与该 gt bbox 的 IOU 值,计算 IOU 值时不考虑坐标,只考虑形状(因为此处 anchor 没有坐标 xy 信息),所以先将 anchor 与 gt bbox 的中心点对齐(简单做法就是把 anchor 的 xy 设置为 gt bbox 的中心点即可),然后计算出对应的 IOU 值,IOU 值最大的那个 anchor 与 gt bbox 匹配,对应的预测框用来预测这个 gt bbox。其余 anchor 暂时算作负样本。
有 1 个情况需要思考清楚:假设有 2 个 gt bbox 的中心都落在同一个网格,且形状差异较大,此时这 2 个 gt bbox 应该会匹配到不同的 anchor,这是我们希望的。但是如果差异比较小,导致都匹配上同一个 anchor 了,那么后一个 gt bbox 会把前一个 gt bbox 匹配的 anchor 覆盖掉,导致前面的 gt bbox 变成负样本了,这就是常说的标签重写问题。
上述匹配规则在不同复现版本里面有不同实现(官方代码也有,但是从来没有开启该设置),基于上述匹配规则并且借鉴 ssd 的做法,可以额外加上一个匹配规则:当每个 gt bbox 和最大 iou 的 anchor 匹配完成后,对剩下的 anchor 再次和对应网格内的 gt bbox 进行匹配(必须限制在对应网格内,否则 xy 预测范围变了),当该 anchor 和 gt bbox 的 iou 大于一定阈值例如 0.7 后,也算作正样本,即该 anchor 也负责预测 gt bbox。这样的结果就是一个 gt bbox 可能和好几个 anchor 匹配,增加了正样本数,理论上会更好。
(2) 忽略属性定义
此时已经确定了所有 anchor 所对应的正负属性了,但是我们可以试图分析一种情况:假设某个 anchor 的预测 bbox 和某个 gt bbox 的 iou 为 0.8,但是在前面的匹配策略中认为其是负样本,这是非常可能出现的,因为每个 gt bbox 仅仅和一个 anchor 匹配上,对于其附近的其余 anchor 强制认为是负样本。此时由于该负样本 anchor 预测的情况非常好,如果强行当做负样本进行训练,给人感觉就是不太对劲,但是也不能当做正样本(因为匹配规则就是如此设计的),此时我们可以把他当做灰色地带的样本也就是忽略样本,对这类 anchor 的预测值不计算 loss 即可,让他自生自灭吧!
故作者新增了忽略样本这个属性(算是 yolo 系列正负样本定义的一个特色吧),具体计算过程是:遍历每个 anchor 的预测值,如果 anchor 预测值和其余所有 gt bbox 的所有 iou 值中,只要有一个 iou 值大于阈值(通常是 0.6),则该 anchor 预测值忽略,不计算 loss,对中间灰色区域就不管了,保证学习的连续性。
1.4 bbox 编解码
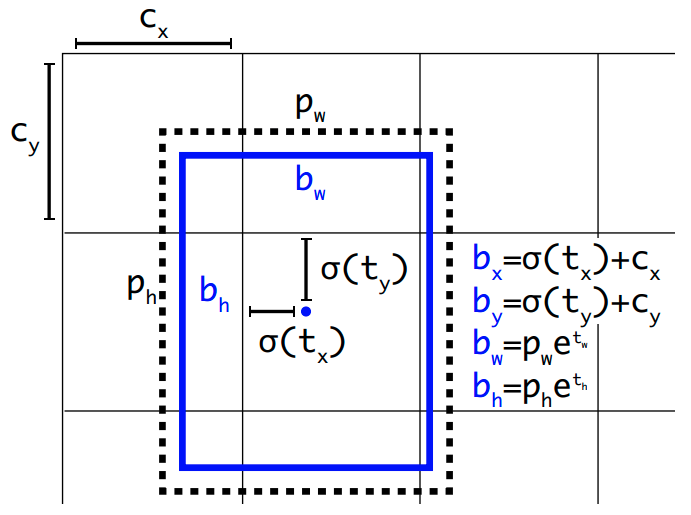
yolov2 的 bbox 编解码结合了 yolov1 和 ssd 的做法,具体是:对于 xy 中心点值的预测不变,依然是预测相对当前网格左上角偏移。但是对于 wh 的预测就不同了,主要原因是有 anchor 了,其 wh 预测值是 gt bbox 的宽高除以 anchor 的 wh,然后取 log 操作即可(和 ssd 的 bbox 编解码是一样的),并且 gt box 和 anchor 尺度都会先映射到特征图上面再计算。可以发现xy 的预测范围是 0~1,但是 wh 的预测范围不定。
确定了编码过程,那么解码过程也非常简单,就是上面图中的公式,cx,cy 的范围是 0~13,因为 xy 预测范围是 0~1,故对预测的 tx,ty 会先进行 sigmoid 操作(yolov1 没有进行 sigmoid),然后加上当前网格左上角坐标,最后乘上 stride 即可得到 bbox 的中心坐标,而 wh 就是预测值 tw,th 进行指数映射然后乘上特征图尺度的 anchor 宽高值,最后也是乘上 stride 即可。
相比于 yolov1 的编解码方式,采用 anchor 有诸多好处,最主要是可以克服 yolov1 早期训练极其不稳定问题,原因是其在早期训练时候每个网格都会输出 B 个任意形状的预测框,这种任意输出可能对某些特定大小的物体有好处,但是会阻碍其他物体学习,导致梯度出现瞬变,不利于收敛。而通过引入基于统计物体 wh 分布的先验 anchor,相当于限制了回归范围,训练自由度减少了,自然收敛更加容易,训练更加稳定了。
1.5 loss 设计

不要被上面的 loss 公式吓到,其实非常简单。首先和 yolov1 一样,所有分支 loss 都是 l2 loss,同时为了平衡正负样本,其也有设置不同分支的 loss 权重值。
(1) bbox 回归分支 loss
首先 1ktruth 的含义是所有正样本为 1,否则是 0,也就是说 bbox 回归分支仅仅计算正样本 loss。truthr 是 gt bbox 的编码 target 值,br 是回归分支预测值 tx,ty,tw,th,对这 4 个值计算 l2 loss 即可。
1t<128000 是指前 128000 次迭代时候额外考虑一个回归 loss,其中 priorr 表示 anchor,表示预测框与先验框 anchor 的误差,注意不是与 gt bbox 的误差,可能是为了在训练早期使模型更快学会先预测先验框的位置。
关于 1t<128000 这个 loss,可以详细说明下,其官方代码写法为:

truth 是已经编码后 xywh 分支的 target 了,可以发现此时 xy label 是假设 gt bbox 中心一定在网格中心,而 wh label 就是 anchor(这个 l.biases 就是对原图尺度的 anchor 除以 stride 后变成特征图尺度的值)除以特征图大小(典型是 13),可以简单认为在每个 gt bbox 所属网格内会附加一个 gt bbox 中心点一定在网格,但是 wh 会依据匹配情况改变的 gt bbox,对于任何一个正样本 anchor,其 xy label 是始终不变的,而 wh label 会随着所属 gt bbox 的匹配情况而改变,也就是说这个 loss 的目的是希望忽略 xy 的学习,而侧重于将预测 wh 学习出 anchor 的形状,可能有助于后面的收敛。但是不可忽略的一个点是:由于这个 loss 和图示下一行的坐标 loss 是一起学习的,就会出现回归分支预测 wh 的含义出现冲突,一个 loss 希望其学习 anchor 的 shape,一个 loss 希望其学习 gt bbox 相对 anchor 的缩放,为了避免这个现象,作者实际上把 1t<128000 这个 loss 仅仅在前期用,并且故意设置权重值比较低(典型值是 0.01)。目前第三方复现都没有考虑这个 loss,可能作用确实很小吧。
需要特别注意的是:由于 bbox 宽高不一致,表现在数值上就会时大时小,对于 l1 或者 l2 来说,梯度就不一样大,这是不好的,因为极端情况就是网络只学习大物体,小物体由于梯度太小被忽略了。虽然前面引入了 log(yolov1 里面是通过平方根克服),但是还可以进一步克服,具体就是基于 gt bbox 的宽高,给大小物体引入一个不一样大的系数,具体是2 - 特征图尺度的 gtbbox 的 w×h,这样对于尺度较小的 boxes 其权重系数会更大一些,可以放大误差,该项权重和 λcoord 上再乘上一个可变因子,该技巧对小物体的 mAP 有较大提升。
(2) 分类回归 loss
分类分支预测值是 bc,truthc 表示对应的 one-hot 类别编码,该分支也仅仅是计算正样本 anchor。
(3) 置信度分支 loss
对于置信度分支 loss 计算和 yolov1 里面完全相同,对于正样本其 label 是该 anchor 预测框结果解码后还原得到预测 bbox,然后和 gt bbox 计算 iou,该 iou 值作为 label,用于表示有没有物体且当有物体时候预测 bbox 的准确性,对于负样本其 label=0。上图中的 1maxIOU<Thresh 其实就是表示负样本,可以看出忽略样本全程都是不参与 loss 计算的。
2 训练流程
(1) 高分辨率图片进行分类器微调训练
YOLOv2 的训练主要包括三个阶段。第一阶段就是先在 ImageNet 分类数据集上预训练 Darknet-19,此时模型输入为 224x224,共训练 160 个 epochs。然后第二阶段将网络输入调整为 448x448,继续在 ImageNet 数据集上 finetune 分类模型,训练 10 个 epochs,此时分类模型的 top-1 准确度为 76.5%,而 top-5 准确度为 93.3%。第三个阶段就是修改 Darknet-19 分类模型为检测模型,并在检测数据集上继续 finetune 网络。在 imagenet 训练两次的原因是直接切换分辨率,检测模型可能难以快速适应高分辨率。
(2) 多尺度训练
由于 YOLOv2 模型中只有卷积层和池化层,所以 YOLOv2 的输入可以不限于 416x416 大小的图片。为了增强模型的鲁棒性,YOLOv2 采用了多尺度输入训练策略,具体来说就是在训练过程中每间隔一定的 iterations 之后改变模型的输入图片大小,例如{320,352,...608},在训练过程,每隔 10 个 iterations 随机选择一种输入图片大小,然后只需要修改对最后检测层的处理就可以重新训练。
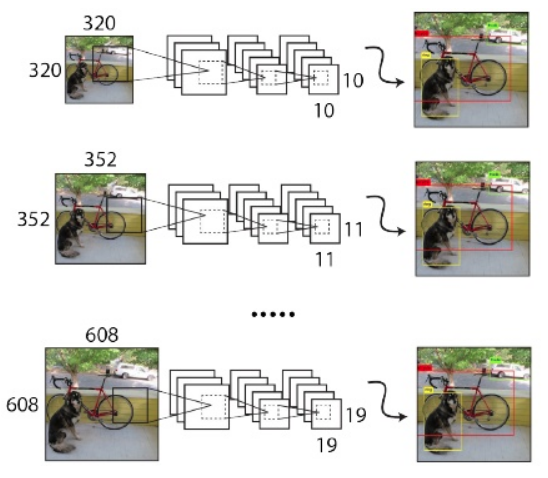
整体训练流程为:
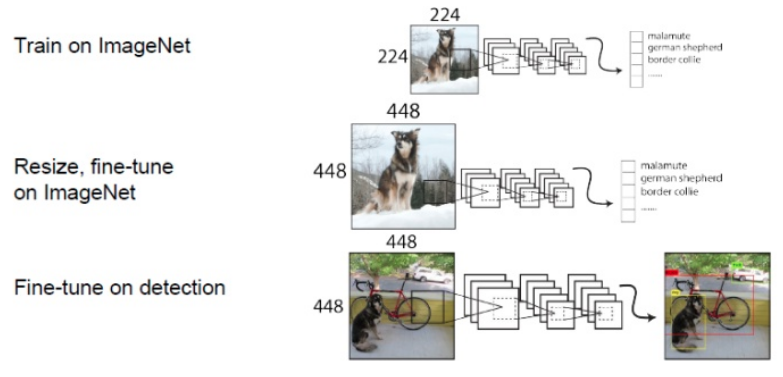
3 测试流程
对于每个预测框,首先根据类别置信度确定其类别与分类预测分值,将类别概率和 confidence 值相乘。然后根据阈值(如 0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码(具体见 1.4bbox 编解码小节),根据先验框得到其真实的位置参数。解码之后,一般需要根据置信度进行降序排列,然后仅保留 top-k 个预测框。最后就是进行 NMS 算法,过滤掉那些重叠度较大的预测框,最后剩余的预测框就是检测结果了。
4 实验分析
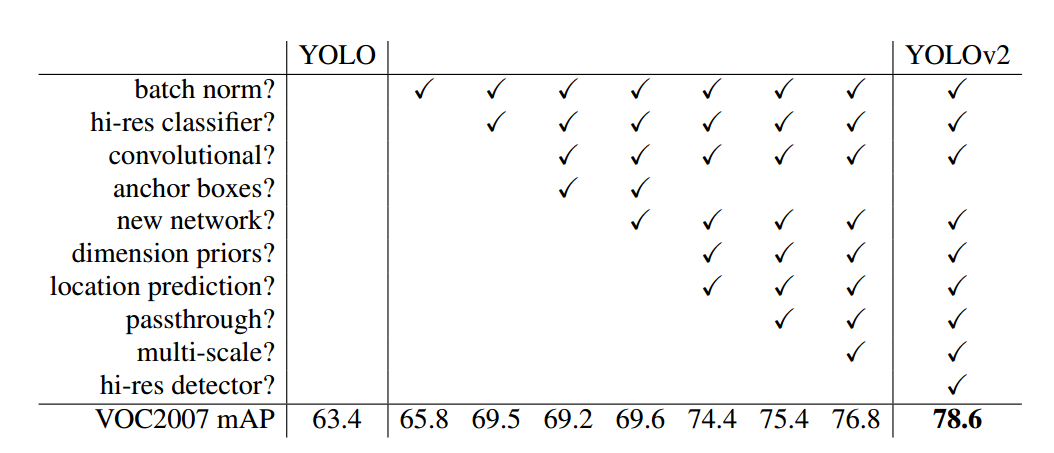
以上是本文所有组件所带来的性能提升。
(1) batch norm
BN 的作用主要是加快收敛,避免过拟合,将其应用于 yolov2 可以提升 2.4%mAP
(2) new network 和 hi-res classifier
new network 指的是所提出的 darknet19,hi-res classifier 高分辨率分类微调训练有助于检测模型快速适应高分辨率,将其应用于 yolov2 可以提升 3.7%mAP
(3) convolutional+anchor boxes
在 yolov1 中其采用全连接层输出,并且设置每个网格预测 B 个物体,边界框的 wh 预测是直接相对整图大小归一化的,而由于各个图片中存在不同尺度和长宽比的 gt bbox,YOLOv1 要学习适应不同物体的形状是比较困难的(因为本身 cnn 就不具有尺度不变性),这会导致 YOLOv1 在精确定位方面表现较差。yolov2 参考了 faster rcnn 或者 ssd 的 anchor bbox 做法来提高召回率,具体是 head 模块输出改为全卷积形式,并且每个网格设置 n 个 anchor bbox,此时就可以真正实现每个网格预测多个物体。 将 anchor boxes 替换掉 yolov1 中的 B 个预测框做法后,YOLOv1 的 mAP 有稍微下降,但是召回率大大提升,由原来的 81%升至 88%,主要原因就是相比 yolov1 的最多只能预测 98 个边界框(7x7x2),变成了最多可以预测 13x13xnum_anchor 个边界框,理论召回率虽然提升了,但是训练策略依然采用的是 yolov1 中的,正负样本不平衡问题应该是加剧了导致 mAP 稍有下降。
(4) dimension priors
其是指的 kmean 自动聚类算法,其最大优点是 anchor 不再需要人为设置,更加智能。
(5) location prediction
其是指本文所提的 bbox 编解码方式。 疑问:为何作者不直接采用 ssd 的编解码方式而要重新设计?在论文中作者也进行了解释,原因是采用 ssd 的 xy 预测方式,在刚开始训练时候其没有任何范围限制,可能预测 bbox 和 gt bbox 偏差很多,导致模型不稳定性,在训练时需要很长时间来预测出正确的 offsets。而如果换成基于网格左上角预测,其会限制在 0~1 范围内,可以使得前期更加稳定,并且通过引入 1t < 128000 这个 loss,可以进一步提高收敛速度。
那么 ssd 算法中训练前期会不会出现不稳定情况?我个人觉得也会但是没有 yolo 中的严重,因为匹配策略不一样。ssd 是完全基于 iou 阈值进行匹配,只要 anchor 设置和 iou 阈值设置合适就可以保证正样本比较多,会更稳定。而 yolo 匹配策略仅仅是每个 gt bbox 一定匹配唯一的 anchor,不管你 anchor 设置的如何,其正样本非常少,前期训练肯定更加不稳定。
(6) passthrough
其是指在 head 部分所提的从高分辨率特征图变成低分辨率特征图的特征融合操作
(7) multi-scale
其是指多尺度训练
(8) hi-res detector
其是指检测器训练采用更高分辨率的图片进行训练可以进一步提高性能
综合性能对比如下: 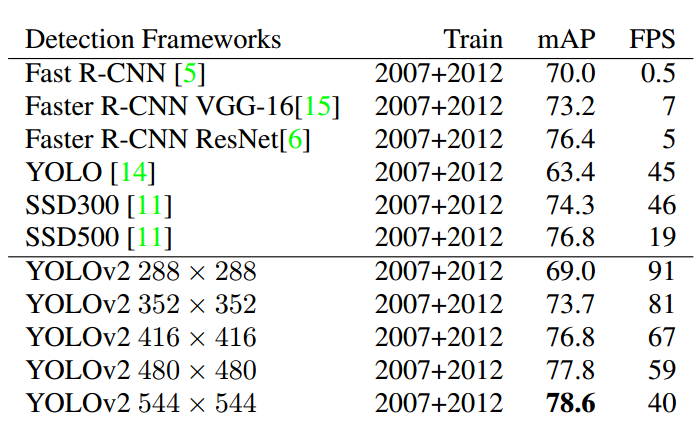
5 总结
通过分析 yolov1 的召回率低、定位精度差的缺点,并且结合 ssd 的 anchor 策略,提出了新的 yolov2 算法,在 BN、新网络 darknet19、kmean 自动 anchor 聚类、全新 bbox 编解码、高分辨率分类器微调、多尺度训练和 passthrough 的共同作用下,将 yolov1 算法性能进行了大幅提升,同时保持了 yolov1 的高速性能。
参考文献
YOLO9000:Better, Faster, Stronger
Last updated