FCOS
FCOS 是目前最经典优雅的一阶段 anchor-free 目标检测算法,其模型结构主流、设计思路清晰、超参极少和不错的性能使其成为后续各个改进算法的 baseline,和 retinanet 一样影响深远,故非常有必要对其进行深入分析。
一个大家都知道的问题,anchor-base 的缺点是:超参太多,特别是 anchor 的设置对结果影响很大,不同项目这些超参都需要根据经验来确定,难度较大。 而 anchor-free 做法虽然还是有超参,但是至少去掉了 anchor 设置这个最大难题。fcos 算法可以认为是 point-base 类算法也就是特征图上面每一个点都进行分类和回归预测,简单来说就是 anchor 个数为 1 的且为正方形 anchor-base 类算法。
在目前看来,任何一个目标检测算法的核心组件都包括 backbone+neck+多尺度 head+正负样本定义+正负样本平衡采样+loss 设计,除了正负样本平衡采样不一定有外,其他每个环节都是目前研究重点,到处存在不平衡问题,而本文重点是在正负样本定义上面做文章。
1 fcos 和 retinanet 算法对比分析
FCOS 结构和 retinanet 几乎相同,但是有细微差别,下面会细说。
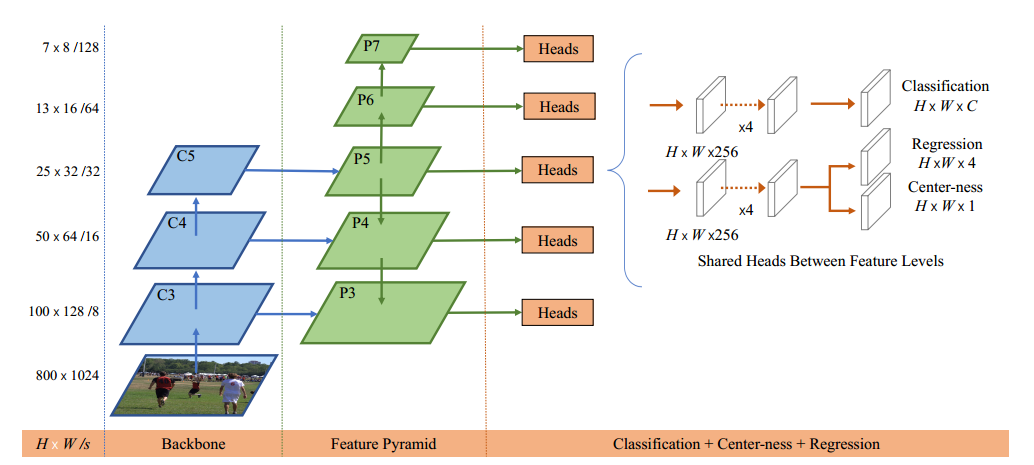
不清楚 retinanet 结构的请看前续解读。retinanet 的结构大概可以总结为:
resnet 输出是 4 个特征图,按照特征图从大到小排列,分别是 c2 c3 c4 c5,stride=4,8,16,32。Retinanet 考虑计算量仅仅用了 c3 c4 c5。
先对这三层进行 1x1 改变通道,全部输出 256 个通道;然后经过从高层到底层的最近邻上采样 add 操作进行特征融合,最后对每个层进行 3x3 的卷积,得到 p3,p4,p5 特征图。
还需要构建两个额外的输出层 stride=64,128,首先对 c5 进行 3x3 卷积且 stride=2 进行下采样得到 P6,然后对 P6 进行同样的 3x3 卷积且 stride=2,得到 P7
下面介绍 fcos 和 retinanet 算法的区别。
1.1 resnet 的 style 模式区别
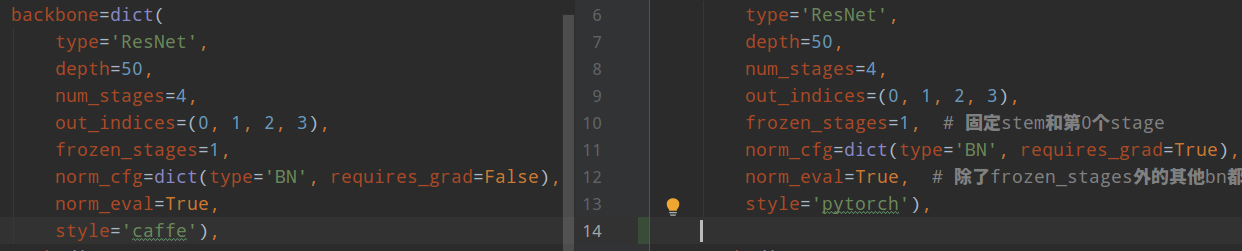
左边是 fcos 配置,右边是 retinanet 配置。
(1) resnet 骨架区别
在 resnet 骨架中,style='caffe'参数和 style='pytorch'的差别就在 Bottleneck 模块,该模块的结构如下:

主干网络是标准的 1x1-3x3-1x1 结构,考虑 stride=2 进行下采样的场景,对于 caffe 模式来说,stride 参数放置在第一个 1x1 卷积上,对于 pytorch 模式来说,stride 放在第二个 3x3 卷积上:
唯一区别就是这个。至于为啥存在 caffe 模式,是因为早期 mmdetection 采用了 detectron 权重(不想重新训练 imagenet),其早期采用了 caffe2 来构建模型,后续 detectron2 才切换到 pytorch 中,属于历史遗留问题。
(2) 骨架训练策略区别
注意看上面的对比配置,可以发现除了上面说的不同外,在 caffe 模式下,requires_grad=False,也就是说 resnet 的所有 BN 层参数都不更新并且全局均值和方差也不再改变,而在 pytorch 模式下,除了 frozen_stages 的 BN 参数不更新外,其余层 BN 参数还是会更新的。我不清楚为啥要特意区别。
总的来说,在 caffe 模式下训练的内存肯定会少一些,但是效果究竟谁的更好,看了下对比结果发现差不多。
1.2 FPN 结构区别

和 retinanet 相比,fcos 的 FPN 层抽取层也是不一样的,需要注意。
retinanet 在得到 p6,p7 的时候是采用 c5 层特征进行 maxpool 得到的(对应参数是 add_extra_convs='on_input',),而 fcos 是从 p5 层抽取得到的(对应参数是 extra_convs_on_inputs=False),而且其还有 relu_before_extra_convs=True 参数,也就是 p6 和 p7 进行卷积前,还会经过 relu 操作,retinanet 的 FPN 没有这个算子(C5 不需要是因为 resnet 输出最后就是 relu)。从实验结果来看,从 p5 抽取的效果是好于 c5 的,baseline 的 mAP 从 38.5 提高到 38.9。
1.3 数据归一化区别
当切换 style='caffe'时候,需要注意图片均值和方差也改变了:
1.4 head 模块区别
和 retinanet 相比,fcos 的 head 结构多了一个 centerness 分支,其余也是比较重量级的两条不共享参数的 4 层卷积操作,然后得到分类和回归两条分支。
2 fcos 算法深入分析
2.1 fcos 输出格式

fcos 是 point-base 类算法,对于特征图上面任何一点都回归其距离 bbox 的 4 条边距离,
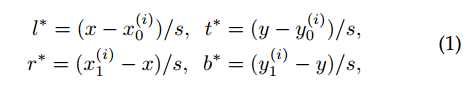
假设 x 是特征图上任意点坐标,x0y0x1y1 是某个 gt bbox 在原图上面的坐标,那么 4 条边的边界(都是正数)其实很好算,公式如上所示。需要注意的是由于大小 bbox 且数值问题,一般都会对值进行变换,也就是除以 s,主要目的是压缩预测范围,容易平衡分类和回归 Loss 权重。
如果某个特征图上面点处于多个 bbox 重叠位置,则该 point 负责小 bbox 的预测。
2.2 正负样本定义
一个目标检测算法性能的优异性,最大影响因素就是如何定义正负样本。而 fcos 的定义方式非常 mask sense,通俗易懂。主要分为两步:
设置 regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),用于将不同大小的 bbox 分配到不同的 FPN 层进行预测即距离 4 条边的最大值在给定范围内
设置 center_sampling_ratio=1.5,用于确定对于任意一个输出层距离 bbox 中心多远的区域属于正样本,该值越大,扩张比例越大,正样本区域越大
为了说明其重要性,作者还做了很多分析实验。
(1) 为啥需要第一步?
regress_ranges 的意思是对于不同层仅仅负责指定范围大小的 gt bbox,例如最浅层输出,其范围是 0-64,表示对于该特征图上面任何一点,假设其负责的 gt bbox 的 label 值是 left、top、right 和 bottom,那么这 4 个值里面取 max 必须在 0-64 范围内,否则就算背景样本。
为啥需要限制层回归范围?目的应该有以下几点:
在 SNIP 论文中说到,CNN 对尺度是非常敏感的,一个层负责处理各种尺度,难度比较大,采用 FPN 来限制回归范围可以减少训练难度
提高 best possible recall
通常我们知道 anchor 设置的越密集,理论上召回率越高,现在 fcos 是 anchor-free,那么需要考虑理论上的最好召回率是多少,如果理论值都比较低,那肯定性能不行。best possible recall 定义为训练过程中所有 GT 的最大召回率,如果训练过程中一个 GT 被某个 anchor 或者 location 匹配上那么就认为被召回了。

low-quality matches 意思是 retinanet 配置中的 min_pos_iou 参数,默认是 0。在不使用 low-quality matches 时候,对于某些 gt,如果其和 anchor 的最大 iou 没有超过正样本阈值,那么就是背景样本,一开启 low-quality matches 则可能能够捞回来,开启这个操作可以显著提高 BPR,从表中也可以看出,从 88.16 变成 99.32。至于在 ALL 模式下为啥不是 1,作者分析原因是有些 bbox 特别小并且挨着,经过下采样后在同一个位置,导致出现相互覆盖。
对于 FCOS,即使在不开启 FPN 时候,其 BPR 也很高,因为其 bbox 中心范围内都算正样本,BPR 肯定比较高,在开启 FPN 后和 retinanet 相比差别不大,对最终性能没有影响。
为了强调 FPN 层的作用性,作者还对模糊样本数进行分析:
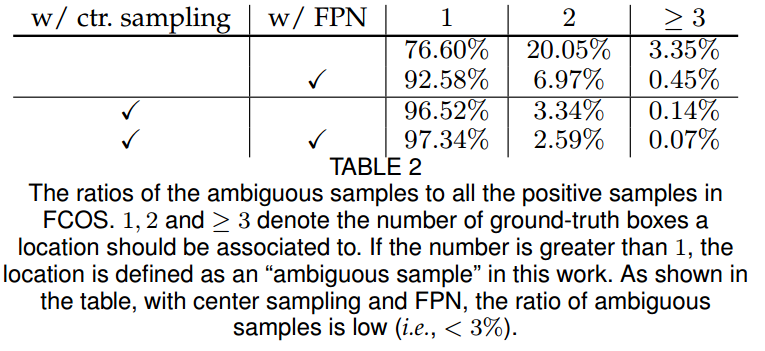
模糊样本就是某个特征图位置处于多个 gt bbox 重叠位置,也就是图表中的大于 1 个数。可以发现在开启 FPN 后,模糊样本明显减少,因为不同大小的 gt bbox 被强制分配到不同层预测了,当结合中心采样策略后可以进一步提高。
(2) 为啥需要第二步?
中心采样的作用有两个
减少模糊样本数目
减少标注噪声干扰

bbox 标注通常都有噪声或者会框住很多无关区域,如果这些无关区域也负责回归则比较奇怪,这其实是目前非常常用的处理策略,在文本检测领域广泛应用。

(a)是早期做法也就是对于本文不采用中心采样策略的做法;(b)是本文做法;(c)是 centernet 做法;(d)是 centernet 改进论文做法。从这里可以看出,(d)的做法应该比 fcos 更加 mask sense,可解释性更强。
总的来说,作者认为FCOS 的功臣可以归功于 FPN 层的多尺度预测和中心采样策略。
(3) 核心代码分析
为了方便理解中心采样策略代码,我对代码进行了分解,具体在 tools/fcos_analyze/center_samper_demo.py。其核心代码逻辑是:
利用 meshgrid 函数获取特征图上面每个点的 2d 坐标
扩展维度,使得所有参数计算的 tensor 维度相同,方便后续计算
如果不采用中心采样策略,则直接对特征点上面每个点计算和所有 gt bbox 的 left/top/right/bottom 值。然后取 4 个值中的最小值,如果小于 0,则该 point 至少有一条边不再 bbox 内部,属于背景 point 样本,否则就是正样本
如果采用中心采用策略,则基于 gt bbox 中心点进行扩展出正方形,扩展范围是 center_sample_radius×stride,正方形区域就当做新的 gt bbox,然后和(3)步骤一样计算正样本即可。还需要注意一个细节:如果扩展比例过大,导致中心采样区域超过了 gt bbox 本身范围了,此时需要截断操作
以上操作就可以确定哪些区域是正样本了,仿真的结果如下所示:

蓝色是 gt bbox,白色区域是正样本区域。从这里也可以看出,其实 FCOS 中心采样策略还有改进空间,因为他的正样本区域没有考虑 gt bbo 宽高信息,对于图片中包含人这种长宽比比较大的场景,这种做法其实不好。需要注意的是为了可视化代码简单,我是直接对特征图 mask 进行上采样得到的,实际上在原图上对应的白色区域是一个点,而不是一个白块。
(4) 理解纠正
我们再来看下上面的一句话:
设置 regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),用于将不同大小的 bbox 分配到不同的 FPN 层进行预测
设置 center_sampling_ratio=1.5,用于确定对于任意一个输出层距离 bbox 中心多远的区域属于正样本,该值越大,扩张比例越大,正样本区域越大
看起来好像没问题,后来我通过正样本可视化分析发现我上面说法是错误的。正确的应该是:
对于任何一个 gt bbox,首先映射到每一个输出层,利用 center_sampling_ratio 值计算出该 gt bbox 在每一层的正样本区域以及对应的 left/top/right/bottom 的 target
对于每个输出层的正样本区域,遍历每个 point 位置,计算其 max(left/top/right/bottom 的 target)值是否在指定范围内,不再范围内的认为是背景
上面两个写法的顺序变了,结果也差别很大,最大区别是第二种写法可以使得某一个 gt bbox 在多个预测层都是正样本,而第一种做法先把 gt bbox 映射到预测层后面才进行中心采样,第二种做法相比第一种做法可以增加很多正样本区域。很明显,第二种才是正确的。
通过正样本可视化分析可以发现:
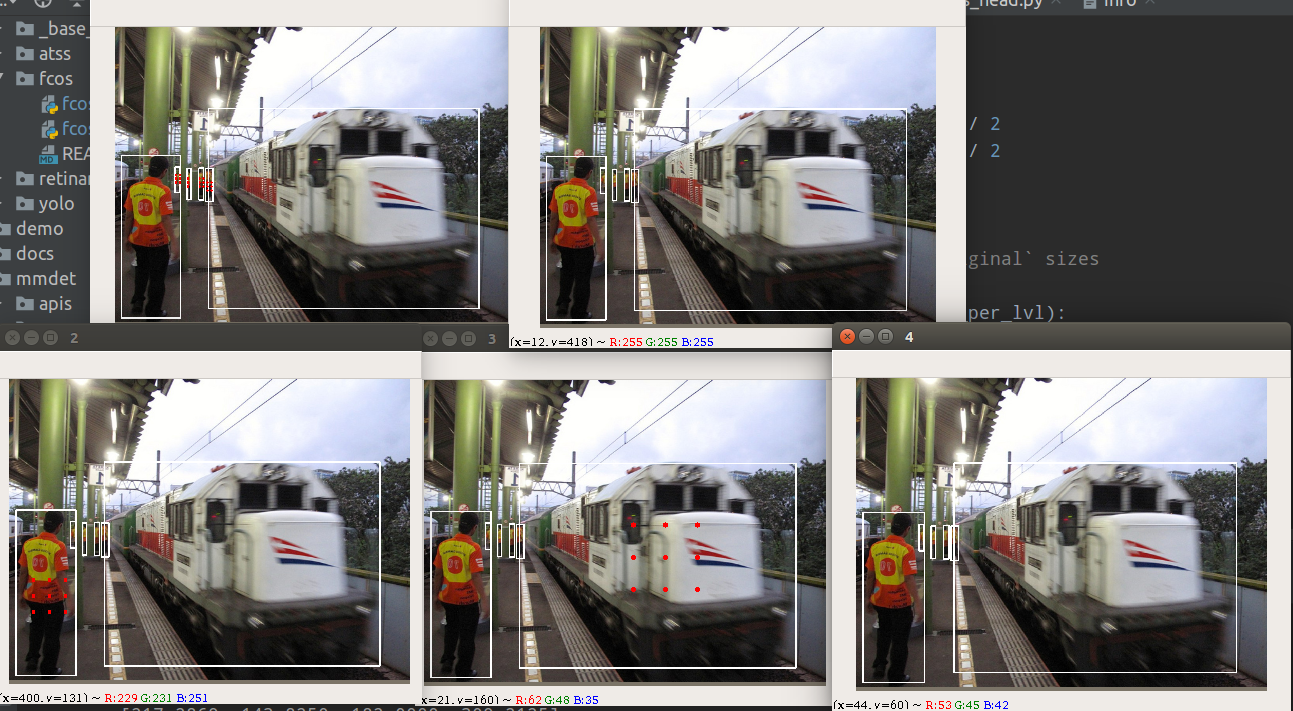
红色点表示正样本 point ,其中 0-4 表示 stride=[8,16,32,64,128] 的输出特征图,代表从小到大物体的预测。

可以看出,其是完全基于回归距离来定义正负样本位置的,但是从语义角度来看,这种设计不够 make sense,因为红色点不是对称分布,特别是上标为 2 的小象内部不算正样本,比较奇怪。从语义角度理解不合理,但是从回归数值范围理解是很合理的。
2.3 loss 计算
在确定了每一层预测层的正负样本后就可以计算 loss 了,对于分类分支(class_num,h',w'),其采用的是 FocalLoss,参数和 retinanet 一样。对于回归分支(4,h',w'),其采用的是 GIou loss,也是常规操作,回归分支仅仅对正样本进行监督。
在这种设置情况下,作者发现训推理时候会出现一些奇怪的 bbox,原因是对于回归分支,正样本区域的权重是一样的,同等对待,导致那些虽然是正样本但是离 gt bbox 中心比较远的点对最终 loss 产生了比较大的影响,其实这个现象很容易想到,但是解决办法有多种。

现象应该和(b)图一致,在靠近物体中心的四周会依然会产生大量高分值的输出。
作者解决办法是引入额外的 centerness 分类分支(1,h',w')来抑制,该分支和 bbox 回归分支共享权重,仅仅在 bbox head 最后并行一个 centerness 分支,其 target 的设置是离 gt bbox 中心点越近,该值越大,范围是 0-1。虽然这是一个回归问题,但是作者采用的依然是 ce loss。很多人反映该分支训练时候 loss 下降的特别慢,其实这是非常正常的,这其实是整图回归问题,在每个点处都要回归出对应值其实是一个密集预测问题,难度是很大的,loss 下降慢非常正常。
需要特别注意的是centerness 分支也是仅仅对正样本 point 进行回归。

通上图可以看出,在引入 centerness 分支后,将该预测值和分类分支结果相乘得到横坐标分支图,纵坐标是 bbox 和 gt bbox 的 iou,可以明显发现两者的一致性得到了提高,对最终性能有很大影响。至于这个图自己如何绘制,有个比较简单的办法:
利用框架进行测试,保存 coco 验证集的预测 json 格式
在写一份离线代码读取该预测 json 和标注的 json,遍历每张图片的预测 bbox 和 gt bbox
对于每张图片的结果,遍历预测 bbox,然后和所有 gt bbox 计算最大 iou,该值就是纵坐标,横坐标就是预测分值(cls*centerness)
所有数据都处理完成就可以上述图表
由于代码比较简单,我这里就不写了。
对于任何一个点,其 centerness 的 target 值通过如下公式计算:

tools/fcos_analyze/center_samper_demo.py 仿真效果如下所示:

越靠近中心,min(l,r)和 max(l,r)越接近 1,也就是越大。
2.4 附加内容
fcos 代码在第一版和最终版上面修改了很多训练技巧,对最终 mAP 有比较大的影响,主要是:
(1) centerness 分支的位置 早先是和分类分支放一起,后来和回归分支放一起
(2) 中心采样策略 早先版本是没有中心采样策略的
(3) bbox 预测范围 早先是采用 exp 进行映射,后来改成了对预测值进行 relu,然后利用 scale 因子缩放
(4) bbox loss 权重 早先是所有正样本都是同样权重,后来将样本点对应的 centerness target 作为权重,离 GT 中心越近,权重越大
(5) bbox Loss 选择 早先采用的是 iou,后面有更优秀的 giou,或许还可以尝试 ciou
(6) nms 阈值选取 早先版本采用的是 0.5,后面改为 0.6
这些 trick,将整个 coco 数据集 mAP 从 38.6 提高到 42.5,提升特别大,新版本的论文中有非常详细的对比实验报告,有兴趣的可以自行阅读。
参考资料
FCOS: A simple and strong anchor-free object detector FCOS: Fully Convolutional One-Stage Object Detection 代码地址
Last updated